Installation
Netdata avec Docker
Malgré les critiques de Docker qui sont formulés, notamment depuis quelques mois depuis l’émergence de solutions alternatives (coucou toi, toi et toi), Docker reste encore une solution de simplicité dans beaucoup de cas. Les gens ont Docker d’installé, savent (à peu près) s’en servir, et c’est assez facile de lancer une application en quelques minutes avec du Docker.
C’est pour ces raisons que je privilégie - du moins pour le moment - encore des installations de tools via Docker. Libre à vous de faire de même ou non !
Quoi qu’il en soit, pour Netdata, l’installation se fait assez facilement, et je vous propose tout de suite de regarder à quoi ça ressemble :
docker run \
--name netdata \
--hostname $(cat /etc/hostname) \
-d \
-p 19999:19999 \
-v /etc/passwd:/host/etc/passwd:ro \
-v /etc/group:/host/etc/group:ro \
-v /proc:/host/proc:ro \
-v /sys:/host/sys:ro \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
--cap-add SYS_PTRACE \
--security-opt apparmor=unconfined \
netdata/netdata
Malgré ce qui est annoncé, il va être rapidement nécessaire de modifier de la configuration pour rendre netdata vraiment utilisable (cf cet article), et pour faire ça, j’aime bien avoir mes fichiers de configurations sur l’hôte, mount dans le conteneur.
Du coup, pour récupérer les fichiers de config importants, on lance notre netdata comme précisé au dessus, puis sur notre host :
curl -o ./netdata.conf http://127.1:19999/netdata.conf
docker exec netdata /bin/sh \
-c 'cat /usr/lib/netdata/conf.d/health_alarm_notify.conf' \
> health_alarm_notify.conf
Ainsi, il nous reste plus qu’à modifier les fichiers comme présenté dans la section suivante, et les monter dans le conteneur en rajoutant 2 flags :
-v `pwd`/netdata.conf:/etc/netdata/netdata.conf \
-v `pwd`/health_alarm_notify.conf:/etc/netdata/health_alarm_notify.conf \
Docker-compose
Évidemment il est possible de transformer facilement le tout en docker-compose.yml (pensez à remplacer /srv/netdata par le path dans lequel vous souhaitez mettre vos fichiers de configs) :
version: '3'
services:
netdata:
image: "netdata/netdata"
hostname: "my-hostname"
ports:
- 19999:19999
cap_add:
- SYS_PTRACE
security_opt:
- apparmor=unconfined
volumes:
- /etc/passwd:/host/etc/passwd:ro
- /etc/group:/host/etc/group:ro
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /var/run/docker.sock:/var/run/docker.sock:ro
- /srv/netdata/conf/netdata.conf:/etc/netdata/netdata.conf
- /srv/netdata/conf/health_alarm_notify.conf:/etc/netdata/health_alarm_notify.conf
Installation directe
Là pas de mystère, on suit la doc et on espère que ça fonctionne :
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
Le processus d’installation qu’ils proposent est plutôt cool en réalité, et assez fonctionnel. Il s’affranchissent d’utiliser le paquet manager de la distribution pour maintenir une version récente de netdata, et malheureusement je n’ai pas assez d’expérience pour dire si ça peut potentiellement poser problème (je suis preneur de retours dans les commentaires si certains veulent présenter leurs expériences).
Configuration
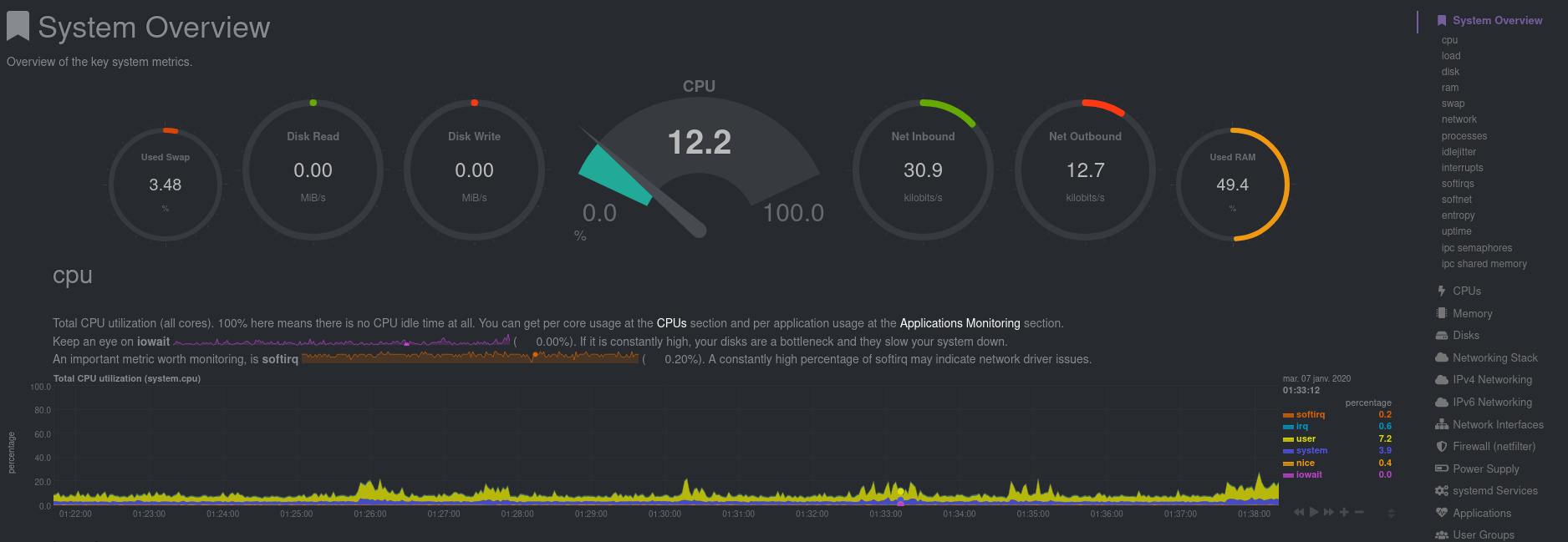
Certaines bases
À ce stade, vous devriez avoir un Netdata fonctionnel, qui collecte des informations sur votre hôte, et qui est accessible sur le port 19999 (attention, de base il est bindé sur 0.0.0.0, voire ::, donc accessible par tout le monde).
Cependant, il est à mon sens nécessaire de modifier quelques lignes de configuration.
La base de données
De base Netdata utilise une sorte de ring buffer pour stocker tous les metrics qu’il collecte. Ce ring buffer contient 3600 entrées par metric, soit 14.4 ko par metric. Comme de base Netdata est également configuré pour collecter chaque metric toutes les secondes, cela fait donc 1h d’historique (logique).
Si j’aime bien la notion de collecte à la seconde, j’aime également avoir un historique un peu plus grand, au minimum 48h. La page de documentation à propos de la base de données indique que si l’on veut 48h de données, avec la configuration de collecte de base, il faudrait 690 Mo de RAM.
Cette même page propose également des solutions d’optimisation en utilisant KSM, mais je ne me suis pas encore penché sur la question. En pratique, je préfère modifier 2 choses pour arriver à mes fins :
- La fréquence de collecte, 3s est largement suffisamment précis pour moi et permet de diviser … par 3 la quantité de RAM disponible.
- Le
memory mode(comprendre moyen de stockage de Netdata) pour ne pas utiliser que la RAM, mais faire un compromis entre les deux. En l’occurrence, Netdata propose lememory mode“dbengine”, qui se trouve être le mode par défaut.
Ce dernier utilise le disk pour stocker la donnée compressée, et un cache en RAM pour limiter les I/O et être un peu rapide tout de même.
Il existe aussi un mode totalement en ram, un de sauvegarde sur le disk, un mode mmap, un mode pour stream uniquement les données à une autre instance, etc.
Pour configurer la base de données, il faut éditer le fichier netdata.conf (soit dans votre dossier de configuration pour Docker, soit dans /etc/netdata/netdata.conf. Si vous ne savez pas où il est, moi non plus, mais peut-être que find -name netdata.conf le sait, lui). Dans la section [global], il faut remplir quelques champs, que voici :
memory mode, fixé àdbenginedans mon cas.historypermet de modifier le nombre d’entrées d’historique à conserver. Cette option est inutile pour le modedbengine.update every, pour sélectionner la fréquence de collecte.page cache sizepermet de sélectionner la quantité de RAM, en Mo, allouée au cache.dbengine disk space, également en Mo, qui permet de choisir la taille que fera la base de données. Une fois la taille maximale atteinte, les données les plus anciennes seront supprimées pour laisser place aux données les plus récentes.
Je suis particulièrement fan de ce fonctionnement. J’adore pouvoir me dire que la maintenance des données les plus anciennes se fait automatiquement, et que quoi qu’il arrive (multiplication par 5 des données à collecter ou de la fréquence de collecte par exemple) Netdata prendra toujours le même espace disque.
Il est intéressant de noter que Netdata en mode dbengine ne stocke les données sur le disque que compressée, et que page par page. Une page fait 4kb, donc met près de 17min à se remplir par metric. Du coup Netdata n’écrit sur le disque pour la base de données que toutes les 17min (par metric) avec une période de collecte de 1s.
Et pour être encore plus efficace, il utilise direct io pour augmenter les perfs et ne pas polluer le cache de linux.
Encore une fois, c’est un mécanisme d’optimisation simple (flag O_DIRECT, man open(2)) mais bien pensé et très efficace, qui me fait encore plus apprecier Netdata.
Il faudra aussi penser pour les utilisateurs de Netdata sous docker à mount également le dossier /var/cache/netdata/dbengine pour sauvegarder la base de données de Netdata.
Génériques
Il est possible par exemple dans le fichier /etc/netdata/netdata.conf de modifier également certaines valeurs par défaut, comme le nom du noeud, les paths pour les logs (debug log, access log, error log), ou bien même des valeurs plus “système” comme la niceness (man 2 nice) ou la stack size de pthread.
Il y a quelques options du dashboard web à consulter, car potentiellement très utile. Je pense notamment à respect do not track policy qui est par défaut à no, ce qui peut chagriner certains, ou bien les options pour HTTPS si Netdata n’est pas protégé par un reverse proxy.
Il est également possible de désactiver certains plugins activés par défaut s’ils sont considérés comme peu pertinent. Je pense par exemple au données des disques ou du réseau, qui sont nombreuses et potentiellement inutiles.
Pour désactiver un plugin, par exemple la collecte sur les disques SSD, il suffit de se rendre à la clé de configuration correspondante dans netdata.conf, et de passer la valeur enabled à no. Pour les SSD, on cherchera la clé [disk.ssd].
Le fichier netdata.conf est auto-généré par Netdata en fonction de la configuration de la machine. Il est déconseillé de le copier de machine en machine, mais bien de le télécharger via une requête HTTP sur l’instance de Netdata pour Docker, comme présenté dans la première partie, ou de modifier /etc/netdata/netdata.conf pour les installations directes.
Une conséquence de la propriété ci-dessus est qu’il est facile de chercher une configuration propre à sa machine. Ainsi, mon pc possèdant une interface vethbe493db, dans le fichier de configuration je retrouve les clés [net.vethbe493db] et [net_packets.vethbe493db].
Configurons manuellement une collecte supplémentaire
Si les “internal plugins” de Netdata sont très bons pour se configurer tout seul, ce n’est pas le cas des “external plugins” qui ont, pour la plupart, besoin de configuration manuelle.
Prenons pour exemple le plugin python.d/nginx, pour collecter des statistiques sur nginx.
location = /_health_status {
stub_status;
}Pour configurer le plugin de collecte de nginx, il va falloir modifier - ou créer - le fichier /etc/netdata/python.d/nginx.conf.
On va rajouter notre configuration pour notre site à la toute fin du fichier, pour ce blog par exemple :
zarakBlog:
url: 'https://zarak.fr/_health_status'
name: 'Blog de Zarak'
update_every: 10
zarakBlogest une clé de configuration qui va correspondre à une entrée (un graph sur Netdata). On peut y écrire ce que l’on veut, ce n’est pas très important, mais si il y a plusieurs site de configurés, ces clés doivent être uniques.urlcorrespond à l’url sur laquellestub_statusest activé.nameest le nom qui sera affiché sur le dashboard Netdata.update_everyest la fréquence de collecte de ce site.
Il y a également des options pour la priorité, pour le délai de retry, …
Une fois l’option activée, et après redémarrage de Netdata, le graphique apparait sur le Dashboard, dans l’onglet adapté :
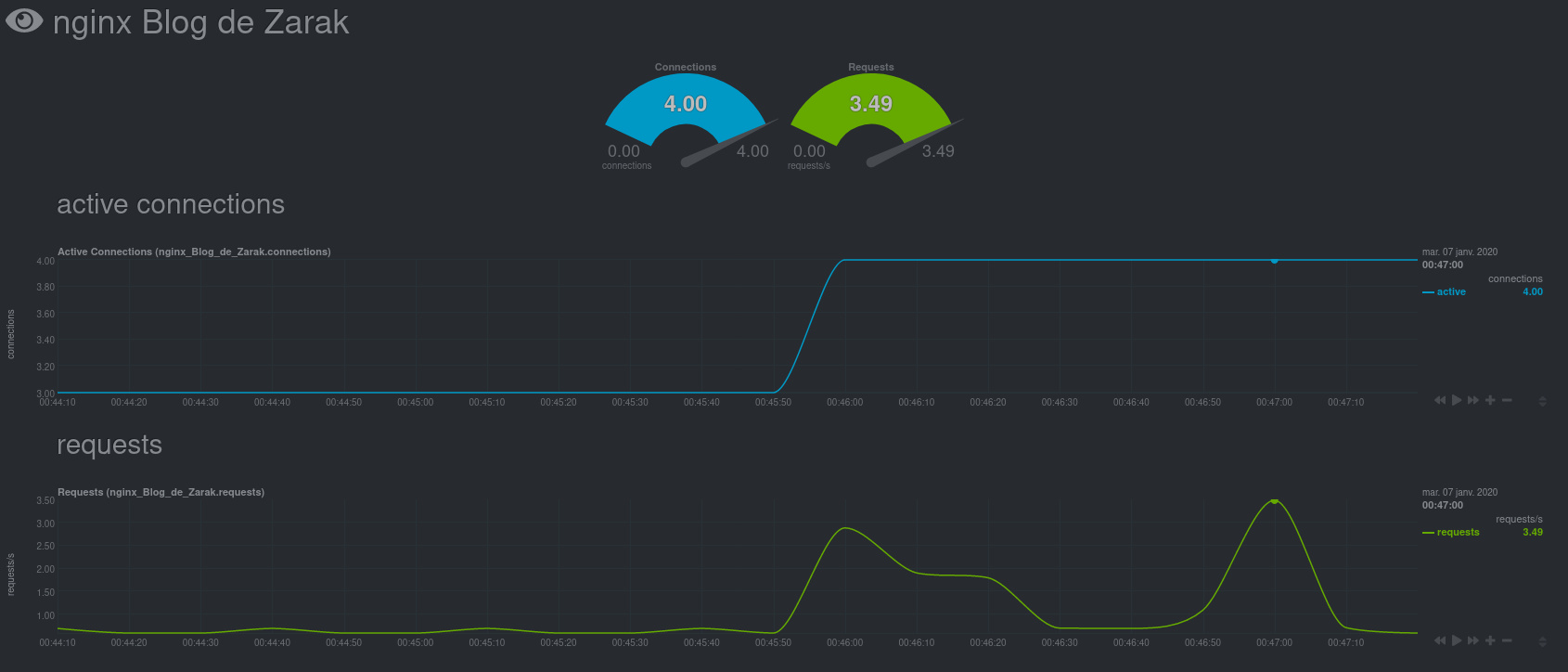
Il est à noter que ce n’est qu’un exemple parmi d’autres. La liste des plugins externes est trouvable aux adresses suivantes :
La liste de plugins est vraiment longue. Chacun y trouvera son bonheur, ou pourra contribuer et écrire son propre plugin. C’est encore une fois ce qui fait une force de Netdata selon moi, même si effectivement la plupart des solutions de monitoring actuelle sont capables de gérer une grosse quantité d’input.
Les alarmes
Configuration
Configurons rapidement une destination pour les alarmes auto-configurées pour nous qui sont prêtes à l’emploi grâce aux dashboards.
La configuration des alarmes se passe dans le fichier health_alarm_notify.conf.
Ce dernier est en réalité un script bash, dans lequel on va remplir des variables avec des valeurs intéressantes.
Configurons par exemple l’envoi sur Slack :
Je pars du principe que le webhook de Slack est déjà configuré et le lien disponible sous la main.
- On se rend directement à la ligne contenant
SEND_SLACKgrâce à un/SLACKsur vim par exemple (sur ma machine, la ligne 369). - On change la ligne pour
SEND_SLACK="YES". - On précise l’URL de webhook avec
SLACK_WEBHOOK_URL="https://hooks.slack.com/services/<token>/". - On précise optionnellement le destinataire avec
DEFAULT_RECIPIENT_SLACKsi l’URL de webhook ne contient pas déjà un destinataire ou un channel. - C’est tout !
En pratique il est possible de modifier assez facilement le destinataire d’un groupe d’alertes, comme celles qui concernent le dev web par exemple, grâce aux variables role_recipients_slack[<team name>]
Chaque alerte configurée possède un role qui correspond au groupe à qui l’alarme s’adresse. Une configuration de base enverra toutes les alertes à un seul endroit.
Pour l’envoi des mail, il a été utile pour moi de setup la variable d’env SMTPHOST
Test
Une fois la méthode de réception des alertes configurées, on teste assez simplement :
# Si installation docker
docker exec -it netdata bash
su -s /bin/bash netdata
export NETDATA_ALARM_NOTIFY_DEBUG=1
/usr/libexec/netdata/plugins.d/alarm-notify.sh test
La poche devrait vibrer à ce moment-là si tout est correct !
Pour prendre en compte les changements de configuration sur les alertes, il n’est pas nécessaire de relancer Netdata, un simple signal SIGUSR2 suffit.
docker-compose kill -s SIGUSR2 netdata par exemple pour docker-compose.
Conclusion
C’est je pense suffisant pour avoir une instance unique de Netdata qui tourne et est configurée au minimum. Si effectivement l’argument de vente “pas de config” est un poil exagéré, il est tout de même vrai que celle ci est assez simple et bien documentée.
Il peut aussi être intéressant de regarder du côté du registry Netdata, ou des options de stream, mais j’en parlerai peut-être dans un autre article si le besoin s’en faire ressentir.

Leave a Comment
Your email address will not be published. Required fields are marked *