Présentation de la problématique
L’objet de cet article est issu du travail que j’ai pu réalisé en tant que SRE à ekee.io, une jeune startup travaillant sur les problématiques liées à la gestion, au partage et à la mise à jour systématique des données. Cette startup développe plusieurs applications backend en Go, avec une architecture de micro-services, et parmi ces micro-services, il en existe un qui s’appelle event-handler.
Le role de l’event-handler est de récupérer des évenements qui ont été publiés sur les files (ou queues, prononcé à l’anglaise) de rabbitmq, les analyser et déclencher des actions spécifiques en fonction de l’événement (envoyer un mail, appeler un webhook, modifier la base de données, …).
Une histoire de CI
Pour respecter au maximum les bons procédés de développement, toutes les applications backend disposent de tests, unitaires et/ou fonctionnels. Ces tests sont lancés manuellement pendant le dev, mais aussi grâce à la CI. La CI d’eKee est Gitlab-CI, dont je ne vanterai pas les mérites ici, mais qui nous permet d’exprimer presque tout ce que l’on veut.
Il est notamment possible de lancer un rabbitmq en tant que service annexe à un job, c’est à dire que le runner de CI, au moment d’exécuter le job des tests, va lancer en parallèle un autre conteneur Docker, le rabbitmq, et le rendre accessible à celui lançant les tests. Le problème de cette solution réside dans la lenteur de rabbitmq à se lancer, la pénibilité pour le configurer, et les ressources qu’il consomme.
Dès lors une solution émerge. Pour la phase de dev, comme les laptops des devs sont déjà très chargés par l’environnement de dev (minikube, les micro-services, la base de données, …), un rabbitmq de dev a été mis à disposition. Rien d’important dessus, utilisable par tout le monde dans la boite facilement, redéployable en quelques secondes, les avantages sont multiples et pour le dev c’est parfait. Pourquoi ne pas utiliser ce rabbitmq dans la CI également ?
Configuration et concurrence
Ce rabbitmq est déjà configuré pour le dev, avec tout ce qu’il faut : vhost, utilisateurs, exchanges, bindings, queues, policies, etc. On pourrait être tenté d’utiliser directement le lapin maître-file, mais un problème de concurrence se pose alors à nous : si le rabbitmq est partagé entre tous (toutes les CI, et les dev), comment s’assurer que le message sera délivré à l’application dans la CI que l’on souhaite tester ? Le message envoyé pourrait très bien être reçu par un autre job de CI fonctionnant en parallèle, ou par un dev ayant son event-handler de lancé et connecté au rabbitmq.
Le test échouerait sans pour autant qu’il y ai un problème dans l’event-handler. Pour pallier ce problème, j’ai donc mis en place un système simpliste mais néanmoins fonctionnel, une configuration temporaire pour rabbitmq à chaque CI.
step by step
Une CI utilisant gitlab-CI pour un projet constitue une pipeline. Une pipeline est composé d’un ou plusieurs jobs, qui peuvent être concurrent ou successif. Le ou les jobs concurrents sont regroupés dans un stage, un étage.
On pourrait donc avoir un premier job pour build à l’étage 1, puis des jobs pour lancer une batterie de tests à l’étage 2, et éventuellement un job pour déployer l’application à l’étage 3 par exemple.
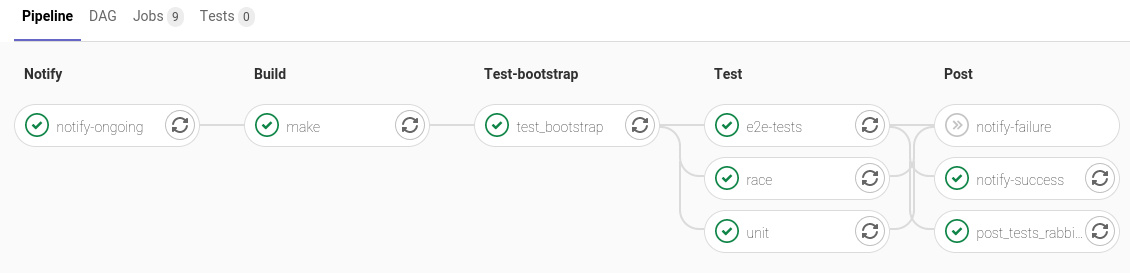
Il est possible d’avoir un contrôle assez important sur le déroulement de l’exécution des stages. Si l’on prend l’exemple ci-dessus, le dernier job notify-failure est grisé car il n’a pas été lancé, tous les jobs précédent ayant réussi.
La solution que j’ai mise en place était donc d’avoir un job (dans son propre stage) avant les tests, qui allait s’occuper de configurer le rabbitmq et de le bootstrapper, pour que les tests puissent se lancer facilement.
Il y a également un job analogue, après les tests, dont le rôle est de nettoyer la configuration temporaire, pour éviter que les configurations devenues obsolète ne s’accumulent sur le rabbitmq.
test_bootstrap et post_test_rabbitmq
Regardons plus en détails comment la configuration se fait.
variables:
EKEE_RABBITMQ_PRODUCER_USER: "${EKEE_RABBITMQ_PRODUCER_USER}"
EKEE_RABBITMQ_PRODUCER_PWD: "${EKEE_RABBITMQ_PRODUCER_PWD}"
EKEE_RABBITMQ_CONSUMER_USER: "${EKEE_RABBITMQ_CONSUMER_USER}"
EKEE_RABBITMQ_CONSUMER_PWD: "${EKEE_RABBITMQ_CONSUMER_PWD}"
EKEE_RABBITMQ_HOST: "example.com"
EKEE_RABBITMQ_DEBUG: "FALSE"
EKEE_RABBITMQ_VHOST: "ci-${CI_PROJECT_ID}-${CI_PIPELINE_ID}"
RABBIT_HOST: "example.com"
RABBIT_PORT: "15672"
stages:
- notify
- build
- test-bootstrap
- test
- post
test_bootstrap:
image: rabbitmqadmin
stage: test-bootstrap
dependencies:
- make
except:
- tags
script:
- ./ci/rabbitmq-ci.sh declare
post_tests_rabbitmq_unset:
when: always
allow_failure: true
image: rabbitmqadmin
stage: post
except:
- tags
script:
- ./ci/rabbitmq-ci.sh deleteCet exemple n’est qu’un court extrait de notre .gitlab-ci.yml, celui-ci fait près de 250 lignes en réalité
Plusieurs choses à remarquer ici. Commençons par la fin (menfou, c’est mon blog, je fais ce que je veux), avec deux propriétés sur le job de fin, when et allow_failure.
Le when: always s’oppose à la valeur par défaut, on_success qui configure le job pour se lancer uniquement si tous les jobs du stage précédent se sont déroulés avec succès. Le always ici permet de nettoyer l’environnement quoi qu’il arrive, même si les tests échouent.
L’option allow_failure à true parle d’elle-même, puisqu’elle autorise ce job à échouer sans que ça impacte le reste de la pipeline (notamment sur le résultat final). Le but ici est de ne pas faire échouer la pipeline pour une mauvaise raison. Il est peu probable que ce job échoue, et si c’est effectivement le cas, ce n’est pas une raison suffisante pour déclarer que l’intégralité de la pipeline a échoué.
Le except: ['tags'] sert juste à éviter de lancer les tests quand on est sur un événement de type tag, c’est à dire lorsque l’on souhaite publier une release.
Les différentes variables en EKEE_* sont des variables d’env pour l’event-handler, pour donner les informations nécessaires à la connexion au rabbitmq. Ces variables sont soit directement définies dans le fichier de configuration de la CI, soit issues de variables stockées dans Gitlab, pour les protéger. Cependant, on note la variable EKEE_RABBITMQ_VHOST qui possède la particularité d’être “dynamique”. En effet, elle dépend de variables mises à disposition par Gitlab, CI_PROJECT_ID et CI_PIPELINE_ID. Ces dernières vont nous permettre d’avoir un nom de vhost unique par pipeline. Et c’est ce vhost qui va être créé, configuré, utilisé et détruit, résolvant ainsi le problème de concurrence d’event-handler sur les messages transitant sur le rabbitmq.
rabbitmqadmin
Mais techniquement, comment fonctionne la création + configuration d’un vhost rabbitmq ? Le lecteur attentif (et qui n’aura pas encore fermé cet onglet) aura remarqué l’image, rabitmqadmin et le script: ./ci/rabbitmq-ci.sh <declare|delete>.
Ces deux éléments ont été créé pour l’occasion. Regardons plus en détails l’image docker, rabbitmqadmin.
FROM alpine:latest
ADD ./docker-entrypoint.sh /usr/bin/rabbitmqadmin-wrapper
RUN apk add --no-cache --update curl python3 bash && \
curl -sL https://raw.githubusercontent.com/rabbitmq/rabbitmq-management/master/bin/rabbitmqadmin -o /usr/bin/rabbitmqadmin && \
chmod +x /usr/bin/rabbitmqadmin && \
chmod +x /usr/bin/rabbitmqadmin-wrapperRien d’incroyable, une alpine python3 qui installe rabbitmqadmin. Ce dernier est un tool permettant d’intéragir avec le plugin de management de rabbitmq, pour automatiser et scripter les actions de déclaration de configuration qu’un utilisateur pourrait faire manuellement sur l’interface web de rabbitmq-management.
On copy également un entry-point.sh, qu’on peut utiliser ou non pour wrapper rabbitmqadmin :
#!/usr/bin/env sh
RABBIT_HOST=${RABBIT_HOST:-example.com}
RABBIT_PORT=${RABBIT_PORT:-15672}
RABBIT_USER=${RABBIT_USER:-root}
RABBIT_PASSWORD=${RABBIT_PASSWORD:-password}
RABBIT_VHOST=${RABBIT_VHOST:-/}
RABBIT_EXTRA_ARGS=${RABBIT_EXTRA_ARGS:-}
/usr/bin/rabbitmqadmin -H "$RABBIT_HOST" -V "$RABBIT_VHOST" -P "$RABBIT_PORT" -u "$RABBIT_USER" -p "$RABBIT_PASSWORD" $RABBIT_EXTRA_ARGS $@Cette image est inspiré de ce projet, qui malheureusement n’a pas été mis à jour depuis un moment et n’est pas suffisament complète pour notre utilisation.
Cette image permet donc d’utiliser rabbitmqadmin sous docker, avec un peu de wrapping pour simplifier l’utilisation (éviter la redondance des certains arguments.
Regardons maintenant le script ./ci/rabbitmq-ci.sh
rabbitmq-ci.sh
#!/usr/bin/env bash
set -feu
IFS= read -r -d '#' DECLARE <<- "EOS"
rabbitmqadmin-wrapper declare vhost name="${RABBIT_VHOST}"
rabbitmqadmin-wrapper declare user name="${EKEE_RABBITMQ_PRODUCER_USER}" password="${EKEE_RABBITMQ_PRODUCER_PWD}" tags=""
rabbitmqadmin-wrapper declare user name="${EKEE_RABBITMQ_CONSUMER_USER}" password="${EKEE_RABBITMQ_CONSUMER_PWD}" tags=""
rabbitmqadmin-wrapper declare permission user="${EKEE_RABBITMQ_PRODUCER_USER}" vhost="${RABBIT_VHOST}" configure="publish.*" write="publish.*" read=""
rabbitmqadmin-wrapper declare permission user="${EKEE_RABBITMQ_CONSUMER_USER}" vhost="${RABBIT_VHOST}" configure="" write="" read="subscribe.*"
rabbitmqadmin-wrapper declare queue name=subscribe.bell auto_delete=false durable=true arguments="{\"x-queue-type\":\"classic\"}"
rabbitmqadmin-wrapper declare queue name=dead auto_delete=false durable=true arguments="{\"x-queue-type\":\"classic\"}"
rabbitmqadmin-wrapper declare queue name=subscribe.search auto_delete=false durable=true arguments="{\"x-queue-type\":\"classic\"}"
rabbitmqadmin-wrapper declare queue name=subscribe.action auto_delete=false durable=true arguments="{\"x-queue-type\":\"classic\"}"
rabbitmqadmin-wrapper declare exchange name="publish.standard" type=direct durable=true internal=false auto_delete=false
rabbitmqadmin-wrapper declare exchange name="dead" type=direct durable=true internal=true auto_delete=false
rabbitmqadmin-wrapper declare binding source="dead" destination="dead" destination_type="queue" routing_key="dead"
rabbitmqadmin-wrapper declare binding source="publish.standard" destination="subscribe.action" destination_type="queue" routing_key="action"
rabbitmqadmin-wrapper declare binding source="publish.standard" destination="subscribe.bell" destination_type="queue" routing_key="bell"
rabbitmqadmin-wrapper declare binding source="publish.standard" destination="subscribe.search" destination_type="queue" routing_key="search"
rabbitmqadmin-wrapper declare policy name="strict-policy" pattern="(publish.*|subscribe.*)" definition="{\"dead-letter-exchange\":\"dead\",\"dead-letter-routing-key\":\"dead\",\"queue-mode\":\"lazy\"}" priority=2 apply-to=all
#
EOS
DELETE="$(cat <<< "$DECLARE" | grep 'declare vhost' | sed -e 's/declare/delete/g')"
if [ "$#" -lt 1 ] || { [ -z "${CI+x}" ] && [ "$#" -ne 2 ] ;}; then
echo "Usage (in CI): ./rabbitmq-ci.sh <declare|delete>"
echo "Usage (Manual): ./rabbitmq-ci.sh <declare|delete> <vhost name>"
exit 1
fi
set -x
if [ "$1" = "declare" ]; then
SCRIPT="$DECLARE"
elif [ "$1" = "delete" ]; then
SCRIPT="$DELETE"
else
echo "Unknown keyword: $1"
exit 1;
fi
if [ -z "${CI+x}" ]; then
docker run \
--rm \
--name rabbitmqadmin \
-e RABBIT_EXTRA_ARGS="--ssl" \
-e RABBIT_VHOST="$2" \
-e EKEE_RABBITMQ_PRODUCER_USER -e EKEE_RABBITMQ_PRODUCER_PWD -e EKEE_RABBITMQ_CONSUMER_USER -e EKEE_RABBITMQ_CONSUMER_PWD \
rabbitmqadmin bash -c "$SCRIPT"
else
export RABBIT_VHOST="${EKEE_RABBITMQ_VHOST}"
bash -c "$SCRIPT"
fiCe script consitue un bon petit paté déjà ! Que faut-il comprendre ?
- On commence par les classiques en bash, un
set -eupour éviter de faire n’importe quoi. On rajoute ici le-fcar on n’a pas besoin de globbing, et on risque de se faire avoir avec les*des regex de configuration -
La première chose que l’on fait réellement, c’est remplir une variable
$DECLAREgrace àread(1)et à un here-document. Cette variable va contenir le mini-script de toutes les choses à déclarer sur rabbitmq. Un changement de la configuration du rabbitmq se fera donc ici.On notera les stratégies pour la constitution du here-doc :
- le
"EOF"quoté permet de ne pas expand les variables contenu dans le here doc à sa création, mais seulement à l’utilisation - le
<<-permet de retirer l’indentation - le
read -d #(et le#à la fin du here-doc) permettent d’eviter que read nereturn 1en ne trouvant pas de\0, ce qui pose problème avec leset -edéfini au dessus. Ce petit hack permet d’avoir tout de fonctionnel, sans avoir le#à la fin de$DECLAREpour autant. Le charactère#est arbitraire, mais intéressant car il ne fait pas parti du here-doc de base (heureusement !) et c’est un commentaire en bash, donc moins de risques d’avoir d’éventuels effets indésirables.
- le
-
On défini notre variable
$DELETEà partir de$DECLAREviased(1), contenant le script opposé. Seul(s) le(s) vhost(s) sont détruit(s), puisque par effet domino, tout ce qui réside sous le vhost est détruit lors de sa destruction.On fera tout de même attention au fait que les utilisateurs ne font pas parti du scope d’un vhost, et qu’ils ne seront pas détruits. C’est volontaire dans ce cas présent, puisque ce sont toujours les mêmes qui sont utilisés (dans la CI et pour le dev)
- Viennent ensuite les phases de détection de l’environnement, si nous sommes dans une CI ou non. Le comportement est légèrement différent en fonction de, comme l’en atteste l’usage.
- En mode manuel, le docker
rabbitmqadminest lancé, et les arguments sont propagés. - Dans le cas contraire, en CI, nous sommes déjà dans
rabbitmqadmin, on peut donc directement exécuter notre script.
Au final
Ainsi, si l’on regarde le processus dans son intégralité, sont bien créées toutes les ressources nécessaires au fonctionnement de notre event-handler, et à ses tests, avant de lancer ces derniers. La suppression après-coup, bien que non nécessaire, permet de libérer un peu ce rabbitmq de développement. Le script mis à disposition dans le repo et utilisé par la CI est également utilisable manuellement. Ainsi, il est très facile pour un dev de se créer un nouvel env sur le rabbitmq pour des nouveaux tests par exemple, ou pour redéployer une configuration identique sur un autre rabbitmq vierge.
Je remercie Alexandre Bernard de m’avoir autorisé à utiliser des extraits du travail que j’ai pu faire à eKee pour constituer cet article.

Leave a Comment
Your email address will not be published. Required fields are marked *