Comment prendre une décision technique
Contexte
Sur notre infrastructure tourne notamment un serveur de news, innd de INN. Ce serveur implémente le Network News Transfer Protocol (NNTP), qui permet d’avoir une sorte de forum pour partager des news, des liens, …
Cet été s’est posé la question de comment obtenir des notifications lorsqu’une news est postée, pour avoir une alerte sur une application type Slack. Si l’idée existait depuis déjà plusieurs mois (le serveur de news en question est utilisé depuis plusieurs années), ce n’est que cet été que le besoin s’est fait ressentir comme urgent.
Je me suis donc penché sur la question, et voici les options qui se sont proposées à moi :
Les options
Parmi les options que j’ai retenues, la plus simple en apparence était d’utiliser les mécanismes de hooks proposées par innd pour exécuter un script de mon cru. Le problème de cette solution est que innd est malheureusement assez obscur. J’ai trouvé la documentation peu claire, mal organisée, et l’architecture des fichiers de configuration assez déroutant. Pas de grosse flèche te disant
tkt, mets un script ici,ou un
hook: /srv/hook.pydansconfig.ymlet c’est bon
Et parmi les rares infos que j’ai réussi à trouver, les hooks sont en perl de base. Je parle pas le perl, et j’arrive même pas à le lire. Bon, j’aurai pu me creuser la tête, et essayer de m’en sortir, mais honnêtement rien qu’en lisant quelques lignes des fichiers où j’aurais dû écrire mon bouzin, je me suis dit qu’il y avait peut-être une autre option.
La documentation mentionnait vaguement une possibilité d’avoir du python, mais sans plus de précision et il fallait recompiler le projet avec des flags en plus. Sauf que d’une part je n’avais aucune idée de quels flags avaient été utilisés pour compiler ce serveur qui fonctionnait déjà bien (filé via le paquet manager), d’autre part la compilation d’un projet de 30 ans (presque littéralement) avait l’air beaucoup plus galère qu’un simple ./configure; make; make install. Et puis galère pour les mises à jour, ça semblait bourbier comme idée.
Assez rapidement j’ai remarqué que le serveur stocke ses news au format text brut dans /var/spool/news, avec un sous-répertoire par newsgroup, un truc un peu hiérarchisé, assez clean. En outre, chaque news - chaque fichier - possède les headers nécessaires pour avoir le contexte (origine, newsgroup, date, etc …) Je me suis donc dit qu’avec un outil de surveillance du filesystem, on aurait pu avoir un évènement déclenché dès qu’un fichier était créé, et faire nos histoires derrière.
Sauf qu’au même moment, j’ai découvert eBPF. Et ça pouvait remplir cette mission. Et ça avait l’air beaucoup plus drôle à utiliser.
eBPF to the rescue
Je ne vais pas présenter eBPF en détails car d’une part je n’ai pas envie de dire de bêtises, et d’autre part car d’autres s’en sont déjà chargé. Cependant, je vais quand même présenter brièvement ce qu’est eBPF, pour pouvoir bien comprendre pourquoi la décision d’utiliser eBPF pour une telle problématique est assez absurde mais drôle.
C’est quoi eBPF ?
Déjà, eBPF signifie extended Berkeley Paquet Filter. C’est une extension de BPF qui a été rajouté à Linux depuis quelques années. BPF permettait de mettre des filtres dans le kernel pour faire du filtre sur du réseau (Berkeley Paquet Filter, socket de Berkeley, tout est lié), un peu comme avec WireShark (je crois d’ailleurs qu’ils utilisent BPF, à vérifier).
La version extended de BPF quant à elle, permet de charger du bytecode dans le kernel pour exécuter des trucs côté kernel. Rien que ça. Alors en pratique, il y a des contraintes. Beaucoup de contraintes même. Exécuter du code côté kernel peut évidemment faire partir en sauce le PC très rapidement, et il y a évidemment beaucoup de choses qu’on ne veut pas laisser faire par un utilisateur, même s’il est root ou qu’il possède la capabilities(8) CAP_SYS_ADMIN.
Par exemple, un code du genre while (true); continue ne serait pas franchement marrant, car il n’y aurait personne pour stopper l’exécution.
eBPF est donc un bytecode, qui peut être produit notamment en compilant un subset du C avec LLVM, qu’on peut attacher à certaines fonctions du kernel.
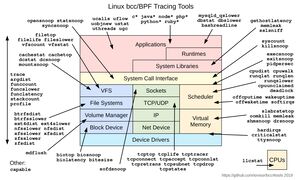
Il existe des bibliothèques pour nous aider à faire de l’eBPF, notamment bpfcc-tools, libbpfcc, …
Détecter des évènements
J’ai donc décidé d’utiliser comme base de travail un script de iovisor/bcc créé par Brendan Gregg de Netflix, filelife.py.
Ce script s’occupe de tracker les fichiers dont la durée de vie est très courte, en s’attachant à 2 fonctions du kernel dont une très intéressante pour moi : vfs_create.
Cette fonction s’occupe d’ajouter un inode dans l’arbre des dentry, donc d’ajouter un fichier dans le VFS. Parfaitement le genre d’évènement que j’ai envie de détecter.
J’ai donc retiré la partie qui s’occupait de mesurer la durée de vie du fichier, et l’attache à vfs_unlink, et il ne me restait plus qu’à récupérer l’évènement en userland.
Des difficultés
Une fois la petite bataille passée, je disposais donc d’un objet python qui contenait quelques informations basiques sur le fichier nouvellement créé :
- le timestamp de création
- le pid du process responsable de la création
- son nom (du moins le début)
- le nom du fichier
Sauf que c’était pas suffisant. Je voulais être certain que le fichier qui venait d’être créé était réellement créé au bon endroit, c’est-à-dire dans un sous-dossier de /var/spool/news, et bien que je possèdais le nom du fichier, je n’avais aucune information sur son path.
Une histoire de boucles
Pas de problème en soi, ma fonction en eBPF prend en argument une partie des arguments de vfs_create, soit la struct inode *dir du fichier à créer, et la struct dentry *dentry qui correspond au noeud du VFS dans lequel ajouter ce fichier.
A partir du noeud du VFS, il est facile de remonter la hiérarchie jusqu’à tomber sur le noeud /, dans ce cas je suis à la racine, le path complet est déterminé, et c’est gagné.
Pas en eBPF.
Pourquoi en eBPF je n’ai pas le droit d’écrire while (1) { continue; } ?
Tout simplement car le script de vérification du bytecode eBPF de linux interdit formellement tout retour en arrière dans le graphe d’exécution du code. Pas moyen d’avoir une boucle, une récursion, même si une analyse statique/formelle peut prouver qu’elle va se finir.
Même un
for (int i = 0; i < 10; ++i)
{
int a = 0;
}
n’est pas autorisé par bpf_check de linux.
Depuis la version 5.3 du kernel, il est possible de faire des boucles dans certains cas
Cependant, ma debian est toujours en 4.19, donc perdoche.
Donc comment faire ?
En étant crade :)
Déroulons la boucle
Connaissant les newsgroups configurés, je sais que la profondeur maximale dans le VFS qui m’intéresse est de 7, j’ai juste à dérouler une boucle qui aurait itéré 7 fois.
Moche mais fonctionnel. Enfin moche … je préfère me voir comme un compilateur intelligent qui décide de faire une super optimisation, sans la partie AVX2 dirons-nous.
Je construis donc un évènement par création de fichier par path du fichier, en utilisant le timestamp comme moyen de relier les bouts paths entre eux.
Le code eBPF ressemble donc à ça :
#include <uapi/linux/ptrace.h>
#include <linux/fs.h>
#include <linux/sched.h>
struct data_t {
u64 ts;
u32 pid;
char comm[TASK_COMM_LEN];
char fname[DNAME_INLINE_LEN];
};
BPF_PERF_OUTPUT(events);
int trace_create(struct pt_regs *ctx, struct inode *dir, struct dentry *dentry)
{
struct data_t data = {};
u32 pid = bpf_get_current_pid_tgid();
// Filter by PID
FILTER;
u64 ts = bpf_ktime_get_ns();
// Does the dentry exists ?
struct qstr d_name = dentry->d_name;
if (d_name.len == 0)
return 0;
if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0) {
data.pid = pid;
}
struct dentry *parent = dentry;
// Am I out of the VFS ?
if (parent == NULL)
return 0;
// This thing actually sucks. Unfortunately, as of spring 2019 there is
// apparently no other way of getting the full PATH of a struct dentry,
// and loops aren't allowed in eBPF, even if they are bounded.
// I hope something better will be found soon. This implementation covers my usecase
// for news notification, but won't work everywhere.
PATH
PARENT
PATH
PARENT
PATH
PARENT
PATH
PARENT
PATH
PARENT
PATH
PARENT
PATH
PARENT
return 0;
};Le code suivant est en réalité contenu dans une variable en python, et avec des supers .replace(), je remplace les macro-like FILTER, PATH et PARENT :
bpf_text = bpf_text.replace("PATH",
"""
// Get parent directory name
d_name = parent->d_name;
// Put it in the exported data
bpf_probe_read(data.fname, sizeof(data.fname), d_name.name);
data.ts = ts;
// Export the data
events.perf_submit(ctx, &data, sizeof(data));
""")
bpf_text = bpf_text.replace('PARENT', """
parent = parent->d_parent;
// Do we hit the root ?
if (parent == NULL || parent == parent->d_parent) {return 0;}
""")Il ne me reste plus en python qu’a collecter les évenement individuellement, et faire tout mon traitement sur ma news :
- Relier les bouts de paths
- Lire la news nouvellement créée
- La parser (un enfer, merci la RFC des headers d’email)
- Faire une pauvre requête web à mon webhook Slack
Et ça fonctionne ?
Eh bien au final, oui. J’ai créé un service systemd pour exécuter mon script en tant que deamon, il est lui-même configuré pour ne regarder que les process qui s’appellent innd (donc pas de traitement inutile pour les autres), et je me retrouve au final avec un système ayant des performances très correctes !
Mon programme n’est en réalité appelé que lorsque la fonction vfs_create est appelée, limitant ainsi la consommation CPU/IO inutile.
Malgré son look bancal et son aspect loufoque, le script est parfaitement stable, puisqu’il tourne sans interruption et sans avoir raté un évènement depuis sa création, il y a 6 mois.
Je trouve ça quand même drôle de me dire qu’un service de notification du genre repose sur un code utilisateur qui s’exécute dans le kernel.

Leave a Comment
Your email address will not be published. Required fields are marked *